
Presso l’Università degli Studi di Torino si svolge ogni anno un laboratorio molto interessante che tratta, declinandolo sotto diverse chiavi di lettura, il tema delle Nuove Tendenze dell’ICT ovvero “dove stiamo andando” per quanto concerne le tecnologie applicate ad un contesto multidisciplinare molto ampio.
Naturalmente la partecipazione agli incontri, che avvengono con relatori interni ed esterni all’Università, è libera e gratuita e, anzi, consigliata perché può dare spunti di riflessione che possono dare origine a nuove idee, decidere di approfondire un certo tema o, perché no, anche a creare una start up per soddisfare uno spazio di mercato che le tecnologie possono aprire.
Tra i tanti argomenti trattati quest’anno si possono citare, ad esempio, la diffusione delle fake news nelle reti social, ontologie e web semantico, strutturare correttamente i dati per la SEO (search engine optimization) e, ancora, interfacce conversazionali (qualcuno ha detto Siri o Alexa?), tecnologie ottiche per l’interazione uomo-macchina e…rullo di tamburi: il progetto “Prismha”.
Entrando nello specifico di questi temi, partiamo dalle fake news, argomento quantomai attuale data la pervasività delle reti social e della nostra interazione con esse.

Come si diffondono le fake news?
Anzitutto occorre chiarire che chi ci “casca” e, inconsapevolmente, la alimenta condividendola, NON è un credulone o un ingenuo. Nel periodo di lock down, più precisamente il 20/03, Sharon Stone dichiara che a Venezia ci sono cigni e delfini perché la natura si riappropria dell’ecosistema data l’assenza dell’uomo.
Bella notizia, diffusa dai media, ma, purtroppo, si rivela una fake news.
Non reale ma realistica, è questa la chiave di volta su cui fa leva la fake news per “spingere” alla sua diffusione.
Ma per capire come si diffonde si adottano tecniche di data analysis, network analysis e modelli di diffusione ovvero è possibile (quantomeno questa è l’idea) capire se si tratti di bufala o no tramite modelli.
I social media sono una risorsa, forniscono dati per fare degli studi; non sono il male.
Esistono relazioni tra fenomeni sociali chiamati segregazione e polarizzazione. Per spiegare la prima si può usare la metafora della distribuzione della popolazione: se parto da una società ben mescolata e lascio libertà di “spostamento”, dopo un po’ noteremo che gli individui tendono a raggrupparsi in modo da stare con persone simili tra loro (in ambito urbanistico può portare, purtroppo, alla ghettizzazione, ma quella è un’altra cosa).
L’utilizzo e l’accesso alle notizie è differente in base alle segregazioni.
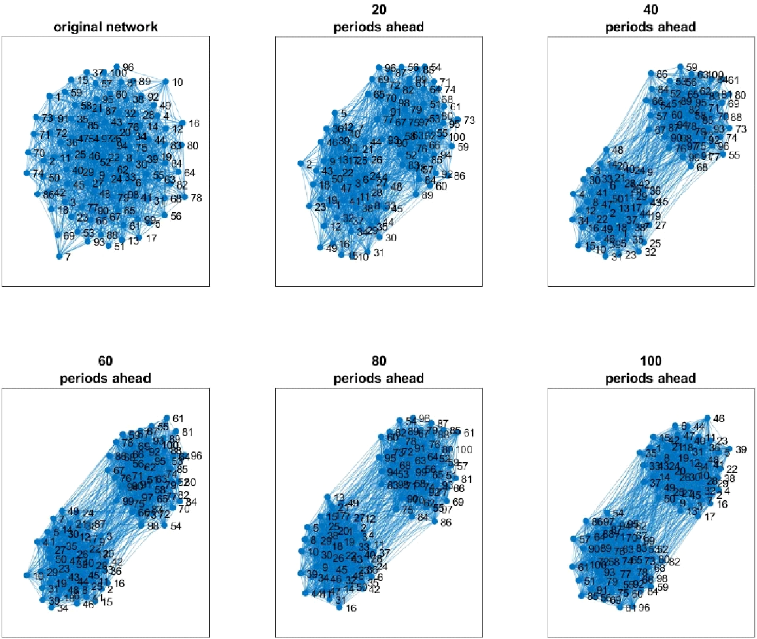
La polarizzazione riguarda, invece, la netta contrapposizione che si viene a creare, appunto, tra due poli, due fazioni, due schieramenti, due opinioni, ecc. quindi tra chi si schiera a favore e chi contro ad una determinata posizione.
Questi, insieme ai concetti di selezione (seleziono gli amici che la pensano come me) e influenza (cerco di attrarre altri a pensare come me) portano alla creazione di modelli capaci di tracciare, e poi prevedere, la diffusione di una determinata notizia, sulla base di vari parametri presi in considerazione.
Quindi…Il fact checking aiuta la diffusione? E le echo chambers (gruppi con forte segregazione e polarizzazione) che ruolo hanno?
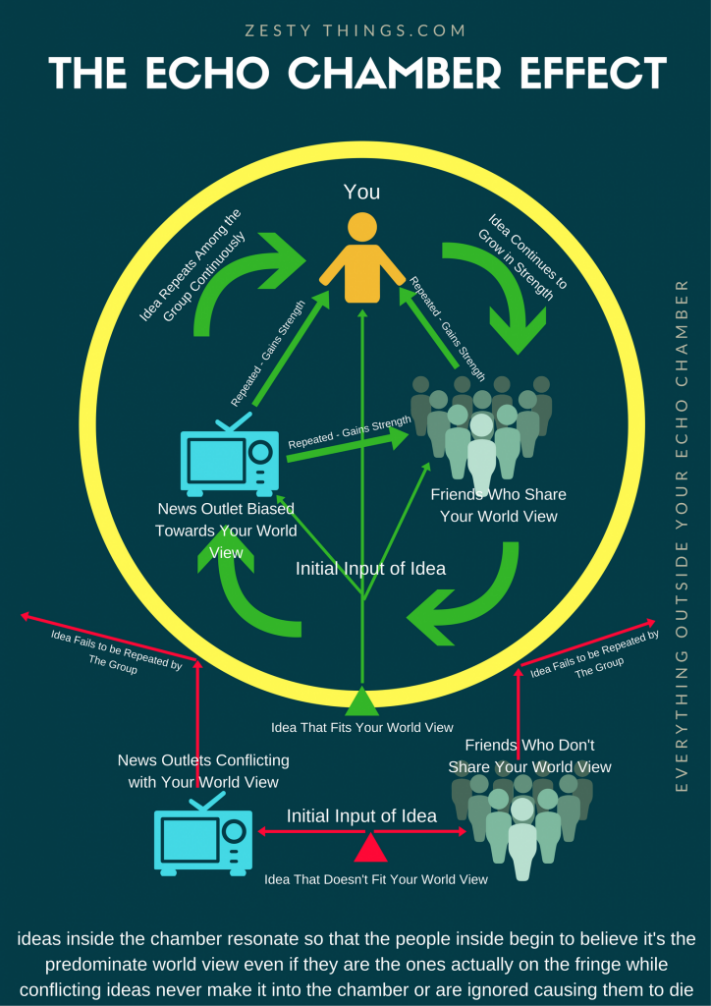
In un social network i nodi sono gli attori e i link sono relazioni.
I nodi possono essere esposti alle notizie da dentro o fuori le sorgenti e via diversi device di comunicazione.
L’obiettivo è quindi di creare un modello per fare previsioni scientifiche, per capire cosa succede sotto certe condizioni.
Tema molto interessante!
ontologie e web semantico
Il web è formato da pagine e pagine e pagine di diversi contenuti (audio, video, testo, ecc.) ma, come sappiamo, nemmeno il computer più potente è in grado di “capire” il vero contenuto (la conoscenza) di tali media. Scopo del web semantico è proprio quello di far comprendere al computer tali contenuti per estrarne informazioni precise e puntuali da far trovare all’utente proprio quando le cerca.

Ciò capita perché le risorse del web sono rivolte ad umani capaci di comprendere e “decifrare” il contenuto istantaneamente, ma serve un enorme lavoro perché l’IA possa fare altrettanto.
Grazie a tecnologie di NLP, machine learning, NERC, sentiment analysis e deep learning, le enormi quantità di dati (Big Data) a disposizione delle aziende possono dare origine a nuove e interessanti applicazioni.
Quindi lo scopo è di arricchire il web con rappresentazioni formali del contenuto semantico delle risorse, in modo da rendere tale contenuto immediatamente accessibile alle macchine (ampliare, non sostituire).
…In realtà…non c’è una diffusione capillare del web semantico, anzi, solo briciole…ma…qualcosa sta cambiando con delle nuove best practices per la pubblicazione dei dati su web: i Linked Data.
Questi ultimi rispettano determinati standard per potersi definire tali e, in particolare, l’uso di RDF (Resource Description Framework con SPARQL per interrogare e manipolare i dataset RDF), significa che, nei testi e nei documenti, vengono “estratte” delle “triple” ovvero contenuti informazionali basati su soggetto, predicato e oggetto e tale è anche il concetto alla base del progetto “Prismha”.
Frutto di una collaborazione tra UniTO e Fondazione Gramsci (Polo del ‘900), il progetto si propone di dar vita ad un “archivista virtuale” basato su tech di IA e Web Semantico che, proprio grazie a quanto sopra esposto, permette di effettuare ricerche secondo le 3 dimensioni ovvero approccio (come), dominio (su cosa) e obiettivo (per cosa) applicato a quanto costituisce un Patrimonio Culturale da preservare nel tempo, ma anche da scoprire e analizzare.
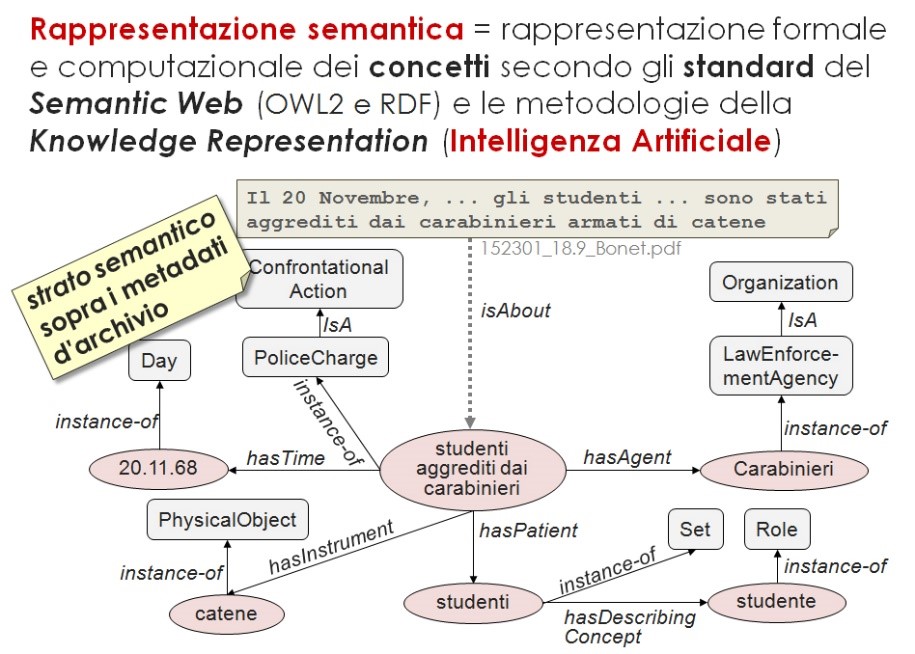
Lo spazio limitato non mi permette di scendere più in dettaglio ma il progetto merita proprio.
Riguardo le tecnologie ottiche per l’interazione uomo-macchina (HCI per gli amici) dare al computer la possibilità di “vedere” l’uomo e l’ambiente che lo circonda sembra quasi magico.
La computer vision è applicabile a qualsiasi ambito, ma, nell’incontro, il focus è stato nel campo medico e, in particolare, per eseguire tele-monitoraggio e tele-riabilitazione basandosi su sistemi di tracking e di recognition.
Le camere RGB-Depth sono dispositivi (tipo webcam ma più evoluti) in grado di mappare pixel di colore e profondità nello spazio. L’insieme delle due informazioni permette la ricostruzione in 3d della scena e il riconoscimento real time del movimento di parti del corpo.
Tutto questo, nel caso presentato, è stato utilizzato per applicazioni di monitoraggio di pazienti affetti da morbo di Parkinson e per creare degli exergames ovvero esercizi in stile gamification per analisi cinematica della prestazione motoria.
Dispositivi nati in ambito videoludico di intrattenimento (KINEKT, HOLOLENS, ecc.) possono diventare invece strumenti utilissimi in contesti diversi da quello per cui erano stati pensati.
E, infine, chiudiamo questa breve rassegna con un tuffo nelle interfacce conversazionali che, sempre più spesso, utilizziamo quasi senza neanche renderci conto.
Siri, Alexa, Cortana (sempre nomi femminili di solito) possono rispondere a molteplici domande e sono in grado di facilitarci la vita nei compiti più svariati.

Basate, anch’esse, su tech di riconoscimento del linguaggio naturale, la loro utilità è massimizzata quando la programmazione del dialogo è molto verticalizzata su un dato argomento. Le “skills” di Alexa, opportunamente progettate, aggiungono funzionalità molto specifiche e riducono quindi la frustrazione di non essere compresi sul contenuto del parlato.
Interessanti e molto variegati gli interventi del laboratorio e ricchi di spunti per approfondire i temi e gli argomenti trattati, sempre con competenza e professionalità dai relatori e dall’organizzatrice Dott.ssa Anna Goy dell’Università di Torino, che desidero ringraziare.
Per concludere…la tecnologia è bella e meravigliosa ma…
(dialogo con SIRI) Ai tempi del COVID:
“Ehi Siri, quando potrò andare al parco?”
“Hai detto: quando dovrò uscire con Marco?”
“No, ho detto parco, parco!”
“Non trovo nessun parco tra i tuoi contatti però ho trovato su internet Parco della Vittoria, vuoi comprarlo?”
😊




